저번 학기에 배운 수업 내용과 과제를 정리
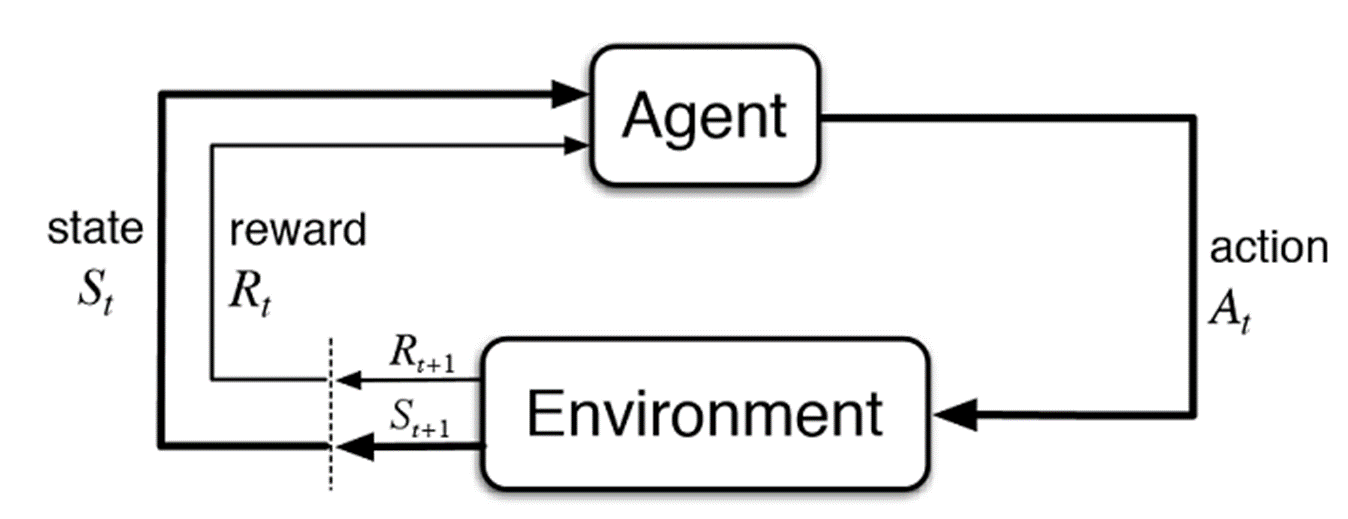
강화학습이란 문제를 해결하는데에 있어서 최적의 방법을 찾는데, 그 시스템 안에서 주어진 상태(State, s) 에서 어떻게 행동(Action, a)하니까 보상(Reward, r)이 얼만큼 나왔다라는 흐름으로 구조를 만들어 보상의 합인 가치값이 가능 크게 만드는 행동을 최적의 해결책으로 선정하는 학습 방법입니다.
강화학습은 크게 3가지 방법으로 나뉩니다.
1. Dynamic Programming (DP)
2. Monte Carlo (MC)
3. Temporal Differnece (TD)
DP방법은 환경모델과 벨만 방정식을 이용해서 모든 경우에 대한 가치를 계산하여 상태 별 가치를 구하고, 그 중에서 가장 높은 가치를 가진 만들어내는 행동을 찾는 방식이다. 모든 경우에 대한 가치를 계산해야 하기 때문에 환경모델 (s에서 a행동을 했을 때 s' 상태가 될 확률, 보상값)을 아는 경우에만 사용이 가능합니다. 그래서 실제 환경에서는 적용하기가 어렵습니다.
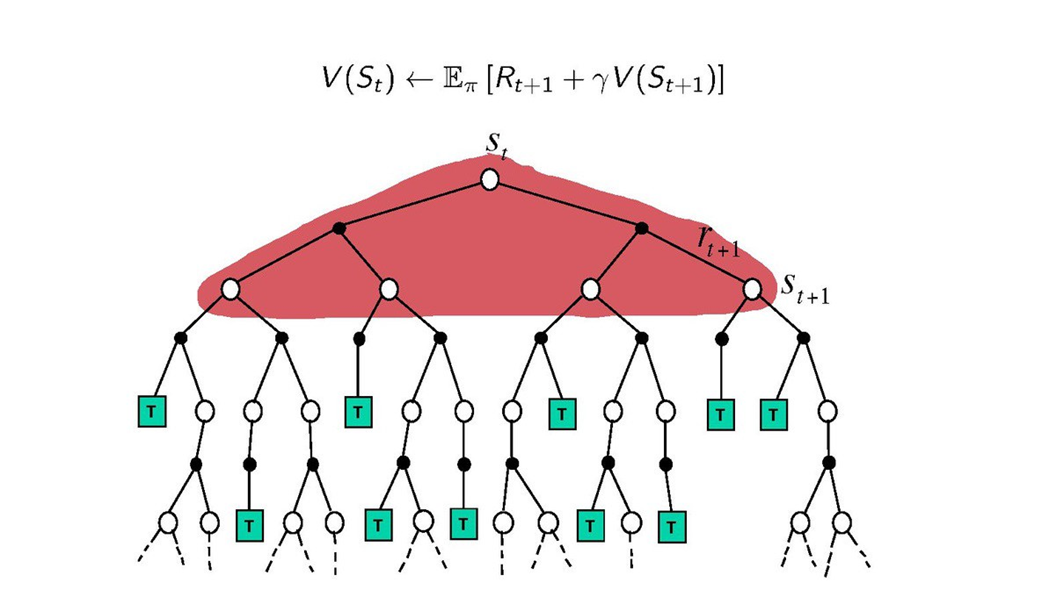
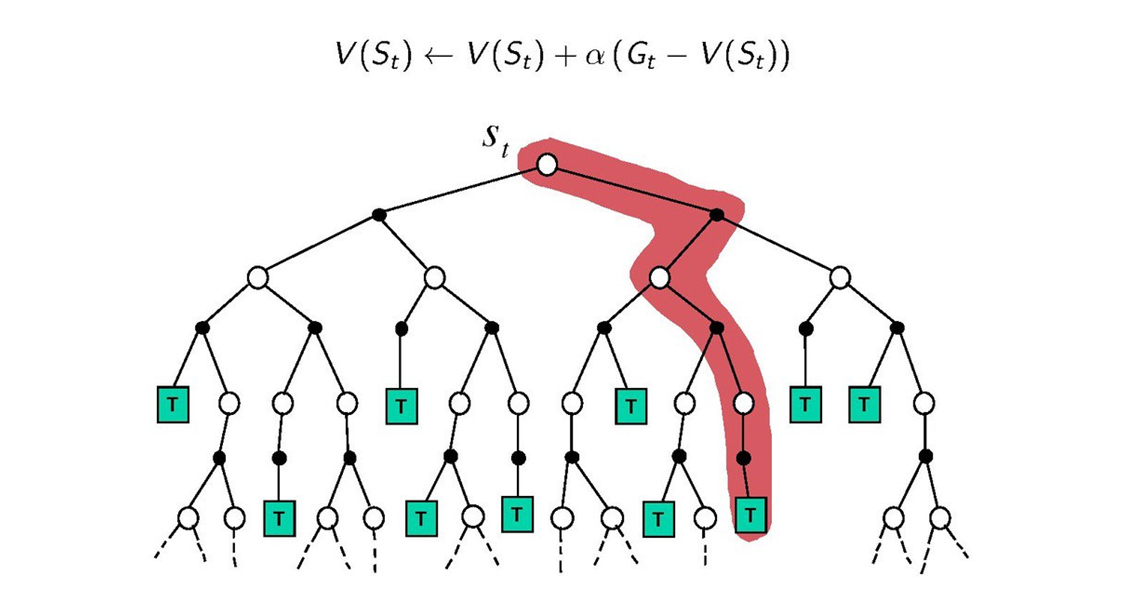
MC방법은 처음 상태에서 시작해서 끝이 날 때까지 진행한 다음 그때 발생한 보상들의 평균값을 계산해서 가장 평균값이 큰 행동을 찾는 방법입니다. MC 방법은 끝날 때까지 기다렸다가 업데이트가 되기 때문에 시간이 오래 걸린다는 단점이 있습니다.
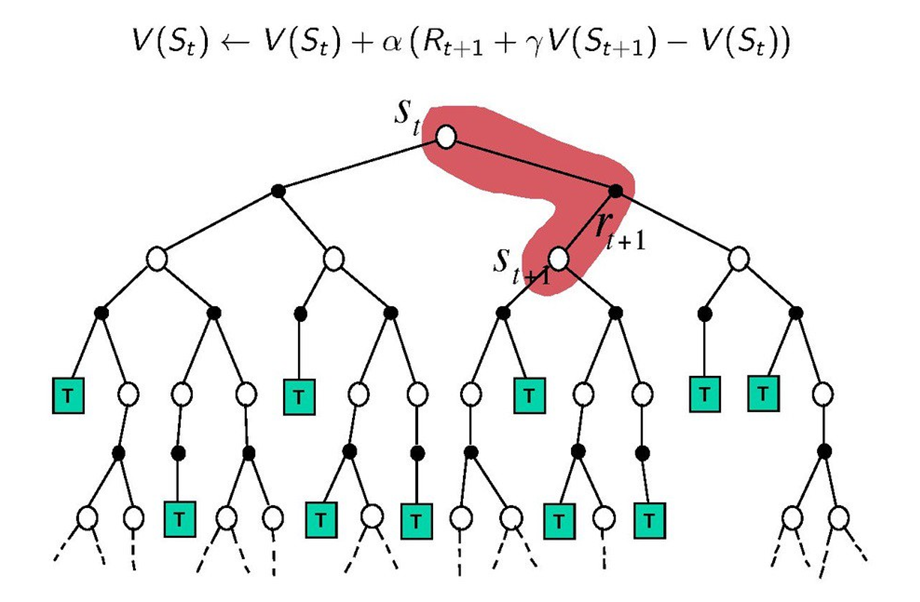
위 두 방법의 단점을 보완하기 위해 두 방법의 장점만 가져와서 합친 방식이 TD방식입니다. 현재상태와 다음상태의 값 이용하여 가치를 업데이트합니다. TD방식은 Sarsa와 Q-Learing 방식으로 나뉩니다.
Sarsa와 Q-Learing 방법으로 Cliff walking 문제를 풀어보도록 하겠습니다. (C++)
#include <iostream>
#include<tuple>
//#include <cstdlib>
//#include <ctime>
using namespace std;
#define UP 0
#define DOWN 1
#define LEFT 2
#define RIGHT 3
#define ALPHA 0.5
double q_table[48][4] = { 0, }; //Q(s,a) 0행렬으로 초기화
class Env
{
private:
bool game_over=false;
int x_pos=0;
int y_pos=0;
int next_x_pos=0;
int next_y_pos=0;
int reward=0;
int gridworld[4][12]={0,};
public:
tuple<int,int, bool> get_reward(int location, int action) // s, a를 받으면 r, s', 게임종료 여부를 반환
{
y_pos = location / 12; //몫->y좌표
x_pos = location % 12; //나머지->x좌표
switch (action) {
case UP:
next_x_pos = x_pos;
next_y_pos = y_pos - 1;
break;
case DOWN:
next_x_pos = x_pos;
next_y_pos = y_pos + 1;
break;
case LEFT:
next_x_pos = x_pos - 1;
next_y_pos = y_pos;
break;
case RIGHT:
next_x_pos = x_pos + 1;
next_y_pos = y_pos;
break;
}
if (next_x_pos == -1) //영역 밖으로 나갔을 때 원위치
next_x_pos += 1;
else if (next_x_pos == 12)
next_x_pos -= 1;
else if (next_y_pos == -1)
next_y_pos += 1;
else if (next_y_pos == 4)
next_y_pos -= 1;
int next_location = next_x_pos + next_y_pos * 12; //다음 상태 location으로 변환
if (next_location > 36 && next_location < 47) //cliff에서는 reward -100 나머지는 -1
{
reward = -100;
next_location = 36; //원위치
//cout << "cliff에 빠졌습니다." << endl;
}
else
reward = -1;
if (next_location == 47) //게임종료여부 확인
game_over = true;
else
game_over = false;
/*
gridworld[y_pos][x_pos] = 1;
gridworld[next_y_pos][next_x_pos] = 1;
for (int i = 0; i < 4; i++)
{
for (int j = 0; j < 12; j++)
{
cout << gridworld[i][j] << " ";
}
cout << endl;
}
*/
return tuple<int, int, bool>(next_location, reward, game_over); // s,a를 넣어서 r과 s' 반환
}
};
class Agent
{
private:
int move;
//double q_table[48][4] = { 0, }; //Q(s,a) 0행렬으로 초기화
public:
int policy_epsilon_greedy(int location) // 액션 선정, 90%확률로 greedy하게 가고, 10% 확률로 0,1,2,3 중 하나 반환
{
//srand((unsigned int)time(NULL));
if (rand() % 10 == 9) //10% 확률로
move = rand() % 4; // 0,1,2,3 중 하나 무작위 반환
else // 나머지 90%로 greedy하게 움직인다.
{
if (q_table[location][0] >= q_table[location][1] && q_table[location][0] >= q_table[location][2] && q_table[location][0] >= q_table[location][3])
move = 0;
else if (q_table[location][1] >= q_table[location][0] && q_table[location][1] >= q_table[location][2] && q_table[location][1] >= q_table[location][3])
move = 1;
else if (q_table[location][2] >= q_table[location][0] && q_table[location][2] >= q_table[location][1] && q_table[location][2] >= q_table[location][3])
move = 2;
else if (q_table[location][3] >= q_table[location][0] && q_table[location][3] >= q_table[location][1] && q_table[location][3] >= q_table[location][2])
move = 3;
}
return move;
}
double sarsa(int location, int action, int reward, int next_location, int next_action)
{
q_table[location][action] = q_table[location][action] + ALPHA * (reward + q_table[next_location][next_action] - q_table[location][action]);
return q_table[location][action];
}
};
int main(void)
{
double episode_reward; //에피소드 안에서 스텝별 보상 저장하는 곳
int cur_location; //현 위치
int cur_action; //현 액션
int reward; //s,a에 의해 발생하는 보상
int next_location; //다음 위치
int next_action; //다음 액션
bool game_over; //게임 종료 여부
int footprint[48] = {0, }; //이동경로
Agent agent; // 에이전트 클래스
Env env; //환경 클래스
for (int i=0; i<500; i++)
{
int footprint[48] = { 0, };
footprint[36] = 1;
game_over = false;
episode_reward = 0;
cur_location = 36; //위치 초기화
cur_action = agent.policy_epsilon_greedy(cur_location); //action 0,1,2,3 중 하나 반환
while (game_over == false) //goalin 할 때까지 반복
{
tuple<int, int, int> env_ = env.get_reward(cur_location, cur_action);
next_location = get<0>(env_);
reward = get<1>(env_);
game_over = get<2>(env_);
//cout << "game over : " << game_over << " reward : " << reward << endl;
episode_reward += reward;
next_action = agent.policy_epsilon_greedy(next_location);
q_table[cur_location][cur_action] = agent.sarsa(cur_location, cur_action, reward, next_location, next_action);
cur_location = next_location;
cur_action = next_action;
footprint[next_location] = 1;
}
cout << "episode : " << i+1 << " reward : " << episode_reward << endl;
if (i == 499)
{
for (int j = 0; j < 48; j++)
{
if (j > 0 && j % 12 == 0)
cout << endl;
cout << footprint[j] << " ";
if (j == 47)
cout << endl;
}
}
}
/*
int a, b, c;
int location = 36;
int action = 0;
Env env;
tuple<int, int, int> first = env.get_reward(location, action);
a = get<0>(first);
b = get<1>(first);
c = get<2>(first);
cout << "다음상태:" << a << " 보상:" << b << " 종료여부: " << c << endl;
*/
//double asdf[][4] = q_table[][4];
}
주어진 문제의 특성을 강화학습의 구조(s, a, r, s', a)에 맞게 잘 작성하고, sarsa의 pseudocode를 참고하면서 최적의 정책을 찾을 수 있도록 코드를 작성해주었습니다.
 |
 |
C++ 언어의 장점으로는 코드를 소스파일과 헤더파일로 나눔으로써 구조화와 디버깅이 용이하다는 것이 있습니다. 그래서 위 코드를 다시 나누어 주었습니다.
소스파일(메인문)
#include "cliffwalking.h"
double q_table[48][4]; //Q(s,a) 0행렬으로 초기화
int main(void)
{
double episode_reward; //에피소드 안에서 스텝별 보상 저장하는 곳
int cur_location; //현 위치
int cur_action; //현 액션
int reward; //s,a 에 의해 발생하는 보상
int next_location; //다음 위치
int next_action; //다음 액션
bool game_over; //게임 종료 여부
int footprint[48] = { 0, }; //이동경로
Agent agent; // 에이전트 클래스
Env env; //환경 클래스
for (int i = 0; i < 500; i++)
{
int footprint[48] = { 0, };
footprint[36] = 1;
game_over = false;
episode_reward = 0;
cur_location = 36; //위치 초기화
cur_action = agent.policy_epsilon_greedy(cur_location); //action 0,1,2,3 중 하나 반환
while (game_over == false) //goalin 할 때까지 반복
{
tuple<int, int, int> env_ = env.get_reward(cur_location, cur_action); //s,a 넣어서 r,s',게임종료여부 반환
next_location = get<0>(env_);
reward = get<1>(env_);
game_over = get<2>(env_);
episode_reward += reward; //한 에피소드 안에서 발생하는 reward 누적
next_action = agent.policy_epsilon_greedy(next_location); // a' 선택
q_table[cur_location][cur_action] = agent.sarsa(cur_location, cur_action, reward, next_location, next_action); //value update
cur_location = next_location;
cur_action = next_action;
footprint[next_location] = 1;
}
cout << episode_reward << endl;
if (i == 499)
{
for (int j = 0; j < 48; j++)
{
if (j > 0 && j % 12 == 0)
cout << endl;
cout << footprint[j] << " ";
if (j == 47)
cout << endl;
}
}
}
}
헤더파일(cpp파일)
#include "cliffwalking.h"
tuple<int, int, bool> Env::get_reward(int location, int action) // s, a를 받으면 r, s', 게임종료 여부를 반환
{
y_pos = location / 12; //몫->y좌표
x_pos = location % 12; //나머지->x좌표
switch (action) {
case UP:
next_x_pos = x_pos;
next_y_pos = y_pos - 1;
break;
case DOWN:
next_x_pos = x_pos;
next_y_pos = y_pos + 1;
break;
case LEFT:
next_x_pos = x_pos - 1;
next_y_pos = y_pos;
break;
case RIGHT:
next_x_pos = x_pos + 1;
next_y_pos = y_pos;
break;
}
if (next_x_pos == -1) //gridworld 밖으로 나갔을 때 원위치
next_x_pos += 1;
else if (next_x_pos == 12)
next_x_pos -= 1;
else if (next_y_pos == -1)
next_y_pos += 1;
else if (next_y_pos == 4)
next_y_pos -= 1;
int next_location = next_x_pos + next_y_pos * 12; //다음 상태 location으로 변환
if (next_location > 36 && next_location < 47) //cliff에서는 reward -100 나머지는 -1
{
reward = -100;
next_location = 36; //원위치
}
else
reward = -1;
if (next_location == 47) //게임종료여부 확인
game_over = true;
else
game_over = false;
return tuple<int, int, bool>(next_location, reward, game_over); // s,a를 넣어서 r과 s' 반환
}
int Agent::policy_epsilon_greedy(int location) // 액션 선정, 90%확률로 greedy하게 가고, 10% 확률로 0,1,2,3 중 하나 반환
{
if (rand() % 10 == 9) //10% 확률로
move = rand() % 4; // 0,1,2,3 중 하나 무작위 반환
else // 나머지 90%로 greedy하게 움직인다.
{
if (q_table[location][0] >= q_table[location][1] && q_table[location][0] >= q_table[location][2] && q_table[location][0] >= q_table[location][3])
move = 0;
else if (q_table[location][1] >= q_table[location][0] && q_table[location][1] >= q_table[location][2] && q_table[location][1] >= q_table[location][3])
move = 1;
else if (q_table[location][2] >= q_table[location][0] && q_table[location][2] >= q_table[location][1] && q_table[location][2] >= q_table[location][3])
move = 2;
else if (q_table[location][3] >= q_table[location][0] && q_table[location][3] >= q_table[location][1] && q_table[location][3] >= q_table[location][2])
move = 3;
}
return move;
}
double Agent::sarsa(int location, int action, int reward, int next_location, int next_action)
{
q_table[location][action] = q_table[location][action] + ALPHA * (reward + q_table[next_location][next_action] - q_table[location][action]);
return q_table[location][action];
}
헤더파일(헤더파일)
#ifndef __cliffwalking_h__
#define __cliffwalking_h__
#include <iostream>
#include <tuple>
using namespace std;
#define UP 0
#define DOWN 1
#define LEFT 2
#define RIGHT 3
#define ALPHA 0.5
extern double q_table[48][4]; //Q(s,a) 0행렬으로 초기화
class Env
{
private:
bool game_over = false;
int x_pos = 0;
int y_pos = 0;
int next_x_pos = 0;
int next_y_pos = 0;
int reward = 0;
public:
tuple<int, int, bool> get_reward(int location, int action); // s, a를 받으면 r, s', 게임종료 여부를 반환
};
class Agent
{
private:
int move;
public:
int policy_epsilon_greedy(int location);
double sarsa(int location, int action, int reward, int next_location, int next_action);
};
#endif프로젝트의 구성은 다음과 같습니다.
메인문은 말 그래도 주요한 실행 명령들이 들어가 있고,
헤더파일에서 cpp파일 안에는 메인문에서 사용하는 클래스들에 대한 설명이 적혀있습니다.
그리고 헤더파일에서 헤더파일은 메인문과 헤더파일에서 사용하는 변수들에 대한 정보가 적혀있습니다.
이렇게 나눠서 작성을 하면 코드가 훨씬 깔끔해져서 보기가 쉽기 때문에 수정, 디버깅 등이 용이합니다.
실행을 해보면
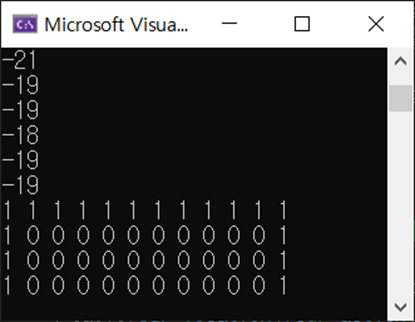
다음과 같이 cliff에 빠지지 않기 위해 가장 안전한 방법을 선택하여 결승점에 도달하는 모습을 볼 수 있습니다.
Q-learning은 Sarsa방법과 다르게 a'를 epsilon-greedy하게 받지 않고 가장 가치가 높은 행동을 a'으로 가져옵니다. 그렇기 때문에 안전하게 가기보다는 위험하더라고 가장 빠른 길을 찾습니다.
메인문
#include "qlearn.h"
double q_table[48][4]; //Q(s,a) 0행렬으로 초기화
int main(void)
{
double episode_reward; //에피소드 안에서 스텝별 보상 저장하는 곳
int cur_location; //현 위치
int cur_action; //현 액션
int reward; //s,a에 의해 발생하는 보상
int next_location; //다음 위치
bool game_over; //게임 종료 여부
int footprint[48] = { 0, }; //이동경로
Agent agent; // 에이전트 클래스
Env env; //환경 클래스
for (int i = 0; i < 500; i++)
{
int footprint[48] = { 0, };
footprint[36] = 1;
game_over = false;
episode_reward = 0;
cur_location = 36; //위치 초기화
while (game_over == false) //goalin 할 때까지 반복
{
cur_action = agent.policy_epsilon_greedy(cur_location); //action 0,1,2,3 중 하나 반환
tuple<int, int, int> env_ = env.get_reward(cur_location, cur_action);
next_location = get<0>(env_);
reward = get<1>(env_);
game_over = get<2>(env_);
episode_reward += reward;
q_table[cur_location][cur_action] = agent.qlearning(cur_location, cur_action, reward, next_location );
cur_location = next_location;
footprint[next_location] = 1;
}
cout << episode_reward << endl;
if (i == 499)
{
for (int j = 0; j < 48; j++)
{
if (j > 0 && j % 12 == 0)
cout << endl;
cout << footprint[j] << " ";
if (j == 47)
cout << endl;
}
}
}
}
헤더파일(cpp파일)
#include "qlearn.h"
tuple<int, int, bool> Env::get_reward(int location, int action) // s, a를 받으면 r, s', 게임종료 여부를 반환
{
y_pos = location / 12; //몫->y좌표
x_pos = location % 12; //나머지->x좌표
switch (action) {
case UP:
next_x_pos = x_pos;
next_y_pos = y_pos - 1;
break;
case DOWN:
next_x_pos = x_pos;
next_y_pos = y_pos + 1;
break;
case LEFT:
next_x_pos = x_pos - 1;
next_y_pos = y_pos;
break;
case RIGHT:
next_x_pos = x_pos + 1;
next_y_pos = y_pos;
break;
}
if (next_x_pos == -1) //영역 밖으로 나갔을 때 원위치
next_x_pos += 1;
else if (next_x_pos == 12)
next_x_pos -= 1;
else if (next_y_pos == -1)
next_y_pos += 1;
else if (next_y_pos == 4)
next_y_pos -= 1;
int next_location = next_x_pos + next_y_pos * 12; //다음 상태 location으로 변환
if (next_location > 36 && next_location < 47) //cliff에서는 reward -100 나머지는 -1
{
reward = -100;
next_location = 36; //원위치
}
else
reward = -1;
if (next_location == 47) //게임종료여부 확인
game_over = true;
else
game_over = false;
return tuple<int, int, bool>(next_location, reward, game_over); // s,a를 넣어서 r과 s' 반환
}
int Agent::policy_epsilon_greedy(int location) // 액션 선정, 90%확률로 greedy하게 가고, 10% 확률로 0,1,2,3 중 하나 반환
{
if (rand() % 10 == 9) //10% 확률로
move = rand() % 4; // 0,1,2,3 중 하나 무작위 반환
else // 나머지 90%로 greedy하게 움직인다.
{
if (q_table[location][0] >= q_table[location][1] && q_table[location][0] >= q_table[location][2] && q_table[location][0] >= q_table[location][3])
move = 0;
else if (q_table[location][1] >= q_table[location][0] && q_table[location][1] >= q_table[location][2] && q_table[location][1] >= q_table[location][3])
move = 1;
else if (q_table[location][2] >= q_table[location][0] && q_table[location][2] >= q_table[location][1] && q_table[location][2] >= q_table[location][3])
move = 2;
else if (q_table[location][3] >= q_table[location][0] && q_table[location][3] >= q_table[location][1] && q_table[location][3] >= q_table[location][2])
move = 3;
}
return move;
}
double Agent::qlearning(int location, int action, int reward, int next_location)
{
if (q_table[next_location][0] >= q_table[next_location][1] && q_table[next_location][0] >= q_table[next_location][2] && q_table[next_location][0] >= q_table[next_location][3])
next_action = 0;
else if (q_table[next_location][1] >= q_table[next_location][0] && q_table[next_location][1] >= q_table[next_location][2] && q_table[next_location][1] >= q_table[next_location][3])
next_action = 1;
else if (q_table[next_location][2] >= q_table[next_location][0] && q_table[next_location][2] >= q_table[next_location][1] && q_table[next_location][2] >= q_table[next_location][3])
next_action = 2;
else if (q_table[next_location][3] >= q_table[next_location][0] && q_table[next_location][3] >= q_table[next_location][1] && q_table[next_location][3] >= q_table[next_location][2])
next_action = 3;
q_table[location][action] = q_table[location][action] + ALPHA * (reward + q_table[next_location][next_action] - q_table[location][action]);
return q_table[location][action];
}
헤더파일(h파일)
#ifndef __qlearn_h__
#define __qlearn_h__
#include <iostream>
#include <tuple>
using namespace std;
#define UP 0
#define DOWN 1
#define LEFT 2
#define RIGHT 3
#define ALPHA 0.5
extern double q_table[48][4]; //Q(s,a) 0행렬으로 초기화
class Env
{
private:
bool game_over = false;
int x_pos = 0;
int y_pos = 0;
int next_x_pos = 0;
int next_y_pos = 0;
int reward = 0;
public:
tuple<int, int, bool> get_reward(int location, int action); // s, a를 받으면 r, s', 게임종료 여부를 반환
};
class Agent
{
private:
int move;
int next_action;
public:
int policy_epsilon_greedy(int location);
double qlearning(int location, int action, int reward, int next_location);
};
#endif
Sarsa코드에서 a'을 선택하는 방법, 가치 계산 방법이 바뀌었고 그에 따라 명령문도 형식에 맞게 조금씩 변경되었습니다.
결과를 보면
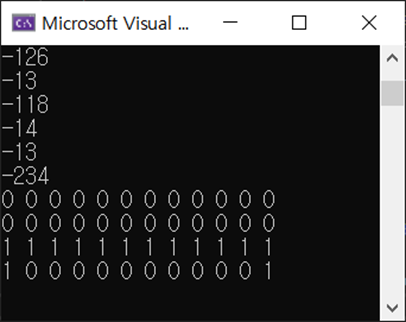
cliff에 가깝게 최단경로로 움직이는 것을 볼 수 있습니다.
여기까지가 cliff walking 문제 해결이었고, 추가로 grid world를 키우고 map 중간에 추가 장애물을 추가하여 Sarsa 방식과 Q-learning 방식을 비교해보았습니다.
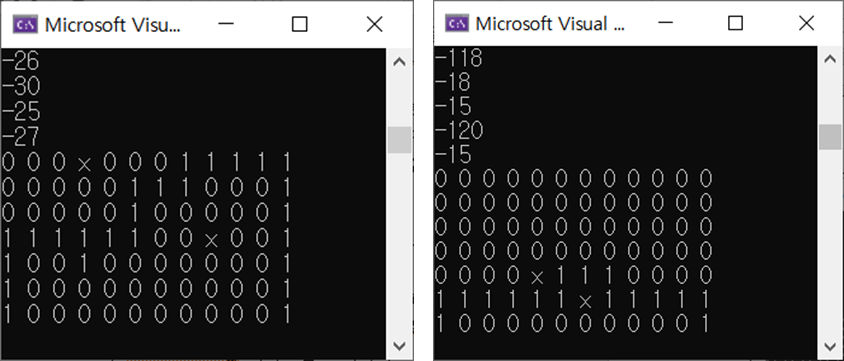
Sarsa는 구덩이에 빠지지 않기 위해 최대한 멀리 떨어져서 움직였고, Q-learning은 구덩이에 빠지진 않되 최단경로로 움직이는 것을 확인할 수 있었습니다.
'정나우 > 코드' 카테고리의 다른 글
| DYROS 강의 정리 (0) | 2022.07.11 |
|---|---|
| ANSYS로 CATIA 모델 정적해석 하기 (0) | 2022.06.12 |
| [오류해결] model serial has no attribute Serial (0) | 2022.05.11 |
| [OpenCV] 동영상에서 이미지 추출하기 (0) | 2022.03.10 |
| 랩뷰 설치, 다운로드 오류 (0) | 2022.02.08 |

댓글